再战commafree code——暴力挑选&优化 EN
引言
在上一篇文章中,我们生成了参数 m=3、n=4 时的所有可能 commafree code。本文将介绍如何从这18个码中挑选出一个最大的子集,使其满足 commafree code 的性质:当集合中任意两个码相连接时,不考虑首尾各n个字母后,中间所有长度为n的子串都不在这个集合中。
由于一个码可以和自身连接,比如选择0001后,序列00010001中的所有长度为4的中间子串(0010、0100、1000)都不能出现在最终集合中。这意味着如果我们选择了某个码,它的所有循环移位都不能再加入集合。因此,对每个主码,我们只需要从它的4个循环移位中选择一个加入集合。
暴力搜索方法
最直接的方法是采用暴力搜索。对每个主码,我们尝试从它的4个循环移位中选择一个,然后验证是否满足 commafree code 的条件。如果满足,就将其加入结果集合。
以下是搜索过程的伪代码:
def pick_code(codes):
if len(codes) == 0:
if len(result) > max_result:
max_result = result
return
for code in codes:
for shift in get_shifts(code):
if is_commafree(result + [shift]):
result.append(shift)
pick_code(codes - {code})
result.pop()
通过实践发现,如果选择策略得当,搜索过程可以快速收敛。例如,按以下顺序选择:
- 第一步选择 0001
- 第二步选择 0011
- 接下来只能依次选择 0002、0021、0111、0211 和 2111(这 5 步都是强制的)
注意第 3 步中,这 5 个选择不是试探,而是唯一合法选项——其他的循环移位已被前两步排除。这种”强制移动”是关键剪枝手段。
动态变量排序
暴力搜索中,我们按固定顺序处理 18 个循环类(x0001, x0002, x0011 …)。但这未必高效——不同分支中,哪个类”最受约束”可能不同。更好的策略是动态排序:每步优先选择剩余合法选项最少的循环类进行分支。这样能更早发现死局并回溯。例如:选完 x0001=0001 后,下一步可以选只剩 2 个选项的 x0012,而不是仍有 3 个选项的 x0122。
优化搜索策略
稀疏集合数据结构
为了高效地记录和更新搜索过程中的选择,我们引入稀疏集合(Sparse Set)这个数据结构。它包含HEAD和TAIL指针,用于维护一个动态集合,同时使用反向数组记录元素在集合中的位置。 它支持快速的添加和删除元素,以及遍历功能。下面简单描述下它的底层数据结构和操作:
分配两组内存中连续的空间,空间大小取决于集合最大个数和集合元素的范围,比如我们只需要存 0~M-1,
那只需要分配2个M长的内存空间就够了。我们用 MEM[HEAD] 表示集合开头,MEM[TAIL] 表示
集合结束后的一个位置,
MEM[IHEAD] 表示0对应在集合的位置,以此类推 MEM[IHEAD+M-1] 是最后的M-1对应的位
置。
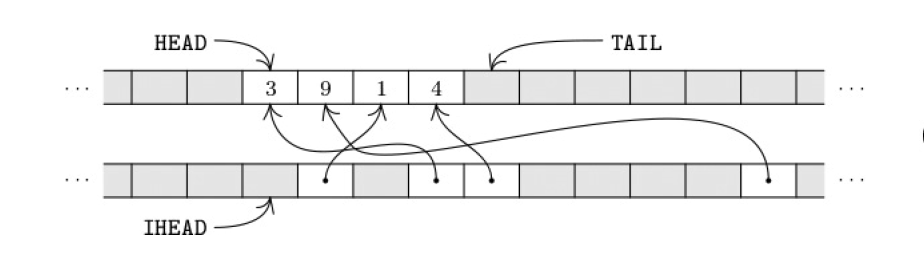
核心操作
- 添加元素
def add_to_set(mem, head, tail, ihead, x):
if head <= mem[ihead + x] < tail:
return
mem[tail] = x
mem[ihead + x] = tail
tail += 1
完成的样子就是前面的图。
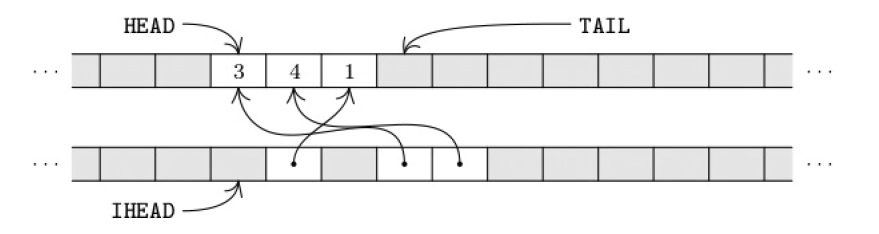
删除元素
比如现在要删除集合中的9,那么我们要把9交换到MEM[TAIL-1]位置,更新MEM[IHEAD],然后TAIL-=1就好,
def remove_from_set(mem, head, tail, ihead, x):
if not (head <= mem[ihead + x] < tail):
return
if head == tail:
return
p = mem[ihead + x] # 记录即将被删元素的指针
tail -= 1
if p != tail:
y = mem[tail]
mem[tail], mem[p] = mem[p], y # 交换被删元素和末尾元素
mem[ihead + x], mem[ihead + y] = tail, p # 交换被删元素和末尾元素反向指针
完成的样子如下:
红蓝绿
当m=3时,只有18个主串需要考虑,搜索空间还不大(注意复杂度时指数级的,因为常数小所以我们说它不大), 但当m=4时事情就变得完全不一样了,因为有60个主串了,看起来时间不可接受了?接下来我们来看看如何只用少量内存空间来完成搜索的更新和回溯。
首先我们有一个函数 \(\alpha\),它将长度 n 的词解释为 m 进制整数,比如 \(\alpha(0102) = (0102)_3 = 0 \cdot 27 + 1 \cdot 9 + 0 \cdot 3 + 2 = 11\)。 然后MEM的0~M-1记录了颜色:
- 红色代表不能选
- 绿色代表选择
- 蓝色代表待定
我们使用7个稀疏集合来维护状态:
- P1(x)、P2(x)、P3(x):记录蓝色词的前缀匹配 \(x_1\star \star \star\),\(x_1x_2 \star \star\),\(x_1x_2x_3 \star\);
- S1(x)、S2(x)、S3(x):记录蓝色词的后缀匹配 \(\star \star \star x_4\),\(\star \star x_3x_4\),\(\star x_2x_3x_4\);
- CL(x):记录蓝色词的循环移位集合 \(\{(x_1x_2x_3x_4),(x_2x_3x_4x_1),(x_3x_4x_1x_2),(x_4x_1x_2x_3)\}\);
每个集合有3个数组,除了上面介绍必备的链表和反向数组外,还有一个数组用来记录TAIL指针。
关闭列表(Closed List)
当某个蓝色词变为绿色时,包含该词的 7 个列表就再无用处(因为只要有绿色词存在,那个前缀/后缀方向已经被封死)。算法将这些列表标记为关闭,将其 TAIL 指针设为 HEAD-1(一个非法值作为标记),之后就不再维护它们。这个优化使得绝大多数列表更新都可以跳过。
Poison List(毒化列表)
选择某个绿色词 \(x_1x_2x_3x_4\) 后,commafree 规则会在后缀和前缀之间建立三条约束:
\[(\star x_1 x_2 x_3,\ x_4 \star \star \star),\quad (\star\star x_1 x_2,\ x_3 x_4 \star\star),\quad (\star\star\star x_1,\ x_2 x_3 x_4 \star)\]每条约束的含义是:左侧模式列表和右侧模式列表中不能同时有绿色词。这些约束构成 poison list。算法在每次做出选择后:
- 如果一条约束两侧都有绿色词 → 死局,立刻回溯
- 如果一侧是绿色词,另一侧还有蓝色词 → 将那些蓝色词全部染红(不可选)
- 如果某侧的列表为空 → 这条约束永远不会触发,从 poison list 删除
例如将 0010 选为绿色后,生成的第一条约束 (*001, 0***) 会立即将 1001 染红(因为 0*** 已有绿色词 0010)。
UNDO 栈——可逆内存
算法维护所有状态的方式是只用一份 MEM 数组,但每次修改都记录到 UNDO 栈:
store(a, v): 将 (a, MEM[a]) 压入 UNDO 栈,然后 MEM[a] ← v
unstore(u0): 弹出直到 UNDO 栈深度为 u0,每次将 MEM[a] 恢复原值
回溯时只需调用 unstore(u0) 将 MEM 还原到进入当前层之前的状态,复杂度正比于本层的实际修改量,而不是整个 MEM 的大小。可选优化:用”时间戳”避免对同一地址多次入栈,首次修改入栈一次,后续同地址修改直接覆盖。
举个栗子
这么讲有点抽象,还是来看个例子
 图中展示了 m=2 时进入第 2 层(选定 0010 为绿色)后 MEM 的变化:0001 和 1001 被染红,P1(0010) 等列表被关闭,poison list 剩余一条
图中展示了 m=2 时进入第 2 层(选定 0010 为绿色)后 MEM 的变化:0001 和 1001 被染红,P1(0010) 等列表被关闭,poison list 剩余一条 (**00, 10**) 约束。
m=4 的实验结果
当 m=4 时有 60 个循环类,上界为 60 个码字。Knuth 的 Algorithm C 给出了如下结果:
| 目标码字数 g | 是否存在解 | 计算量 |
|---|---|---|
| 60 | 不存在 | 13 megamems |
| 59 | 不存在 | 177 megamems |
| 58 | 不存在 | 2380 megamems |
| 57 | 1152 个解 | ~22800 megamems |
搜索过程中 UNDO 栈最深不超过 2804,poison list 最多同时有 12 条约束——说明这个精心设计的数据结构极其紧凑。
小结
本文介绍了构建 commafree code 集合的基本思路和关键数据结构,包括:稀疏集合、红/蓝/绿三态、7 种前后缀列表、关闭列表优化、poison list 剪枝,以及 UNDO 栈实现可逆内存。这些组合在一起构成了高效的 Algorithm C。

